This article provides an in-depth guide on Kubernetes Pods, covering their deployment, scaling, and management within a Kubernetes cluster.
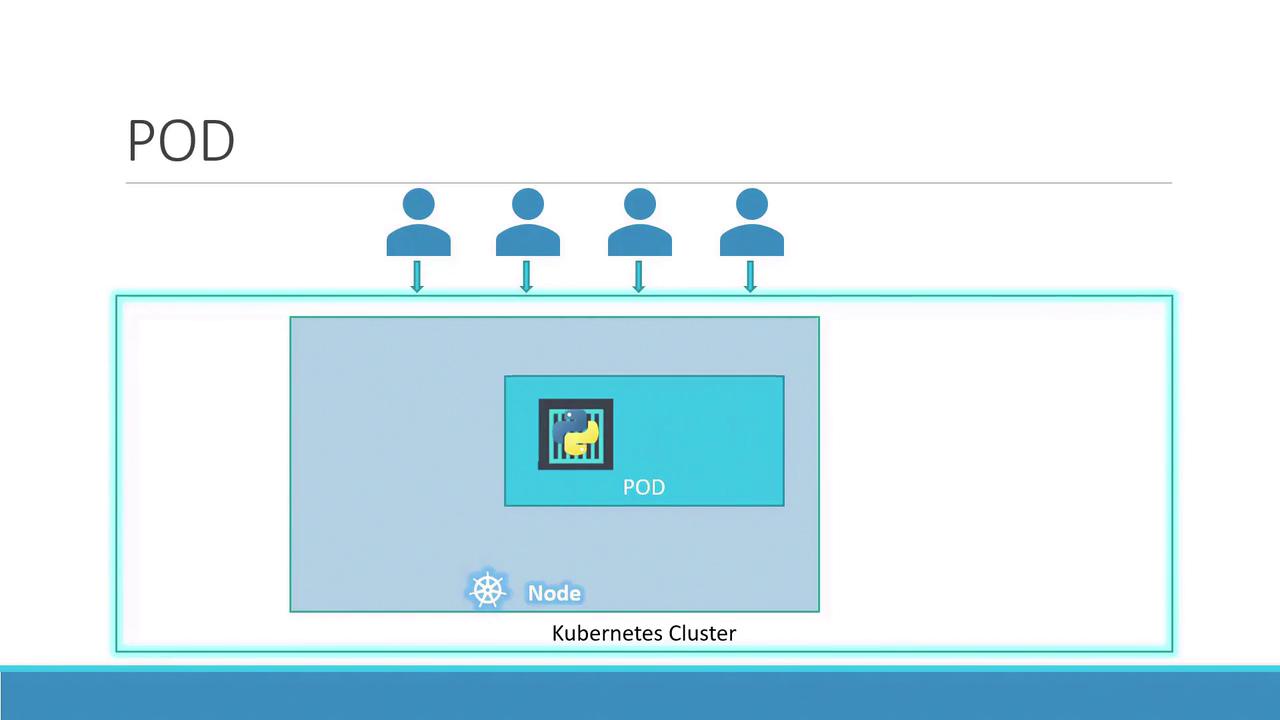
Welcome to this in-depth guide on Kubernetes Pods. In this article, we assume your application is already developed, built into Docker images, and hosted on a Docker repository (such as Docker Hub). We also assume that your Kubernetes cluster is configured and operational—whether it is a single-node or multi-node cluster. With Kubernetes, the goal is to run containers on worker nodes, but rather than deploying containers directly, Kubernetes encapsulates them within an object called a pod. A pod represents a single instance of an application and is the smallest deployable unit in Kubernetes.
In the simplest scenario, a single-node Kubernetes cluster may run one instance of your application inside a Docker container encapsulated by a pod.
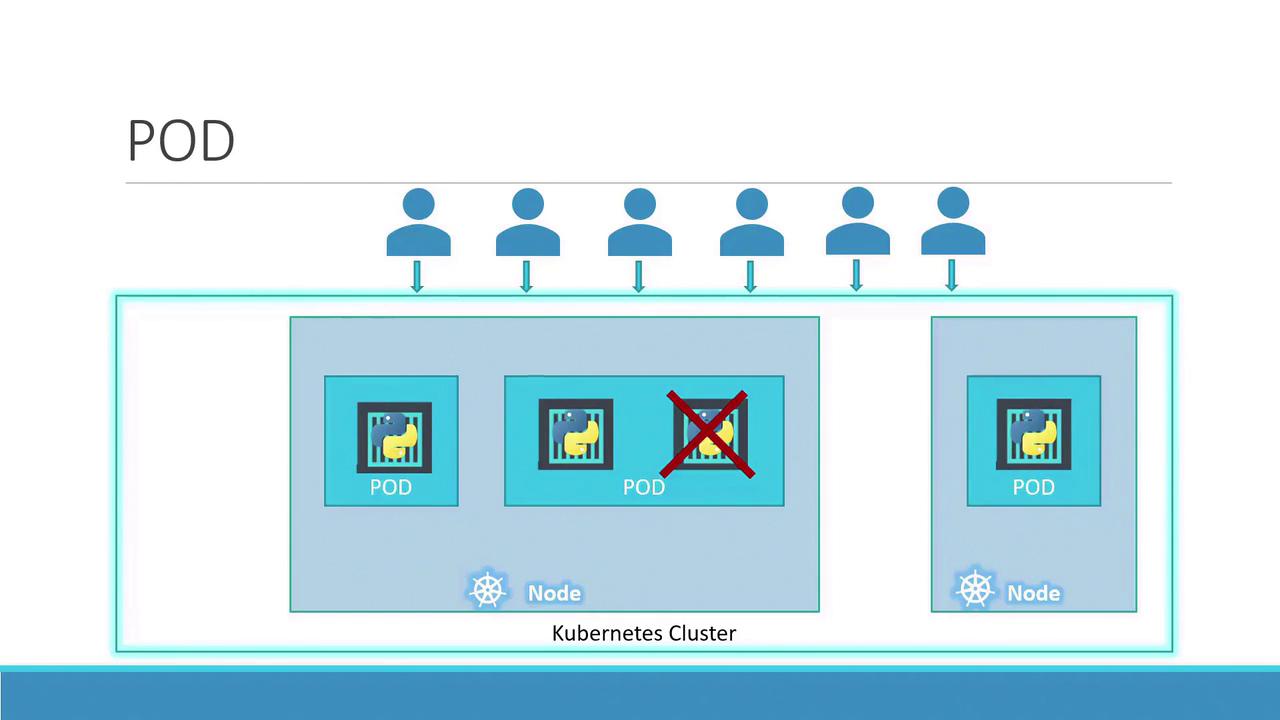
When user load increases, you can scale your application by spinning up additional instances—each running in its own pod. This approach isolates each instance, allowing Kubernetes to distribute the pods across available nodes as needed.
Instead of adding more containers to the same pod, additional pods are created. For instance, running two instances in separate pods allows the load to be shared across the node or even across multiple nodes if the demand escalates and additional cluster capacity is required.
Note
Remember, scaling an application in Kubernetes involves increasing or decreasing the number of pods, not the number of containers within a single pod.
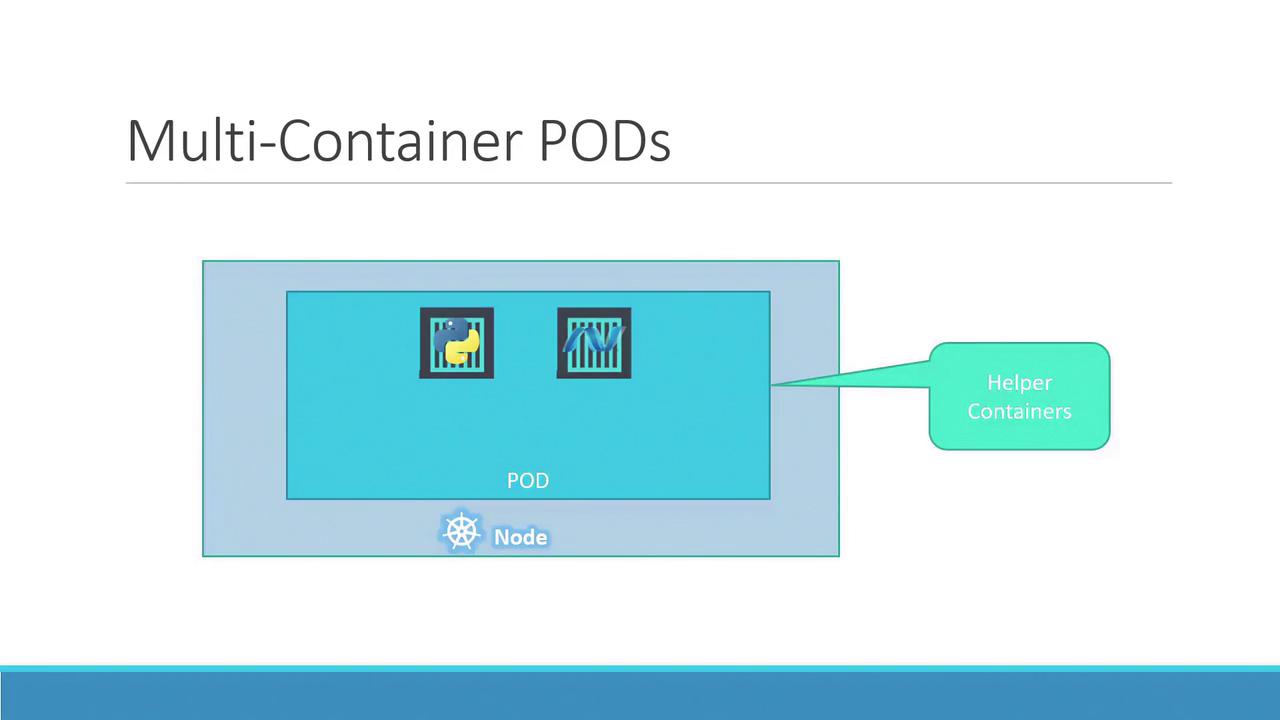
Typically, each pod hosts a single container running your main application. However, a pod can also contain multiple containers, which are usually complementary rather than redundant. For example, you might include a helper container alongside your main application container to support tasks like data processing or file uploads. Both containers in the pod share the same network namespace (allowing direct communication via localhost), storage volumes, and lifecycle events, ensuring they start and stop together.
To better understand the concept, consider a basic Docker example. Suppose you initially deploy your application with a simple command:
When the load increases, you may launch additional instances manually:
Now, if your application needs a helper container that communicates with each instance, managing links, custom networks, and shared volumes manually becomes complex. You’d have to run commands like:
docker run helper --link app1
docker run helper --link app2
docker run helper --link app3
docker run helper --link app4
With Kubernetes pods, these challenges are resolved automatically. When a pod is defined with multiple containers, they share storage, the network namespace, and lifecycle events—ensuring seamless coordination and simplifying management.
Even if your current application design uses one container per pod, Kubernetes enforces the pod abstraction. This design prepares your application for future scaling and architectural changes, even though multi-container pods remain less common. This article primarily focuses on single-container pods for clarity.
Deploying Pods¶
A common method to deploy pods is using the kubectl run command. For example, the following command creates a pod that deploys an instance of the nginx Docker image, pulling it from a Docker repository:
Once deployed, you can verify the pod's status with the kubectl get pods command. Initially, the pod might be in a "ContainerCreating" state, followed by a transition to the "Running" state as the application container becomes active. Below is an example session:
kubectl get pods
# Output:
# NAME READY STATUS RESTARTS AGE
kubectl get pods
# Output after a few seconds:
# NAME READY STATUS RESTARTS AGE
# nginx-8586cf59-whssr 1/1 Running 0 8s
At this stage, note that external access to the nginx web server has not been configured. The service is accessible only within the node. In a future article, we will explore configuring external access through Kubernetes networking and services.
Yes 👍 — using a Kind (Kubernetes-in-Docker) cluster is actually a much clearer way to demonstrate multi-container Pods than the Docker example. Instead of manually linking containers, you can show how Kubernetes naturally runs two containers in the same Pod sharing network and storage.
Below is a simple Kind-based demo you can run locally.
1. Create a Kind cluster¶
First install and start a cluster with Kind.
Verify it works with kubectl:
2. Create a Multi-Container Pod¶
Create a file called pod.yaml.
This pod has:
- main container → Python web server
- helper container → writes logs to a shared volume
apiVersion: v1
kind: Pod
metadata:
name: multi-container-demo
spec:
volumes:
- name: shared-data
emptyDir: {}
containers:
- name: main-app
image: python:3.9
command: ["sh", "-c"]
args:
- python -m http.server 8000 && sleep 3600
volumeMounts:
- name: shared-data
mountPath: /data
- name: helper
image: busybox
command: ["sh", "-c"]
args:
- while true; do date >> /data/log.txt; sleep 5; done
volumeMounts:
- name: shared-data
mountPath: /data
Apply it:
3. Verify the Pod¶
Check the pod:
Inspect containers:
You will see two containers in the same pod.
4. Demonstrate Shared Storage¶
Open a shell in the main container:
Check the shared file:
You’ll see timestamps continuously written by the helper container.
5. Demonstrate Shared Network¶
Because containers share the same network namespace, they can talk via localhost.
For example, the helper container could call the Python server:
This works without any service or networking setup because both containers share the Pod network.
✅ Why this example is better than the Docker one
It shows the three real Kubernetes pod guarantees:
- Shared network (
localhost) - Shared storage (
emptyDirvolume) - Shared lifecycle (containers start/stop together)
All of this works automatically inside a Pod.
💡 If you want, I can also show you a much more realistic Kubernetes multi-container pattern (like app + log sidecar or app + nginx reverse proxy) that is commonly used in production.